

Machine Learning
Simple linear regression
Understanding Data

- Visualizing One-Dimensional & Multi-Dimensional Data.
- Using PCA, Clustering, K-Means, and Topic Models.
- Structured vs. Unstructured Data
Prediction

- Supervised Learning.
- Regression.
- Classification
- Neural Networks.
Decision Making
- The Optimal Decision in Presence of Uncertainty.
- Dynamic vs. Static Environment.
- High to Low Information Rate.
- Using Model Predictive Control, Markov Decision Process, Multi-Armed Bandit, and Reinforcement.
Causal Inference

- Cause and Effect Relationship.
- Thoughtful Experiment Design.
- Randomized Control.
- Hypothesis Testing.
- Synthetic Control.
- Time-Series Forecasting
ML Task
Binary classification
The Ttask of classifying the elements of a given set into two groups, predicting which group each one belongs to.
About this course: Machine learning is the science of getting computers to act without being explicitly programmed. In the past decade, machine learning has given us self-driving cars, practical speech recognition, active web search, and a vastly improved understanding of the human genome. Machine learning is so pervasive today that you probably use it dozens of times a day without knowing it. Many researchers also think it is the best way to make progress towards human-level AI. In this class, you will learn about the most effective machine learning techniques, and gain practice implementing them and getting them to work for yourself. More importantly, you’ll learn about not only the theoretical underpinnings of learning but also gain the practical know-how needed to quickly and powerfully apply these techniques to new problems. Finally, you’ll learn about some of Silicon Valley’s best practices in innovation as it pertains to machine learning and AI. This course provides a broad introduction to machine learning, data mining, and statistical pattern recognition. Topics include: (i) Supervised learning (parametric/non-parametric algorithms, support vector machines, kernels, neural networks). (ii) Unsupervised learning (clustering, dimensionality reduction, recommender systems, deep knowledge). (iii) Best practices in machine learning (bias/variance theory; innovation process in machine learning and AI). The course will also draw from numerous case studies and applications so that you’ll also learn how to apply learning algorithms to building smart robots (perception, control), text understanding (web search, anti-spam), computer vision, medical informatics, audio, database mining, and other areas.
Welcome to Machine Learning! In this module, we introduce the core idea of teaching a computer to learn concepts using data—without being explicitly programmed. The Course Wiki is under construction. Please visit the resources tab for the most complete and up-to-date information.
How to Learn Machine Learning
Having the goal of “learning machine learning” is daunting. I’ve found the best way to make it tractable is to approach it in phases. Each phase should include at least one track that builds practical skills and one track focused on theoretical foundations. Additionally, it’s always worth surveying the field at your current level of fluency to be on the lookout for the next phase of studies and to continue to build a mental map of interconnected topics that may be prerequisites for the techniques and applications that you find most exciting.
Each track should focus on a specific curriculum resource, and then draw on supporting resources. For instance, you might choose a specific book or MOOC course you want to work through, and then draw on several related resources to cross-reference as you proceed. Sticking with a single main resource is important to stay focused; it’s really easy and tempting to jump around various resources without making as much progress past introductory material. It’s worth spending time upfront researching curriculum options before deciding; I usually find several good resources on a topic and do some initial skimming before deciding which becomes the primary resource, bookmarking the rest as supporting
Phase 1: Applied Machine Learning & Probability & Statistics
Phase 1, which took me about 5 months to complete full-time studying, includes two tracks:
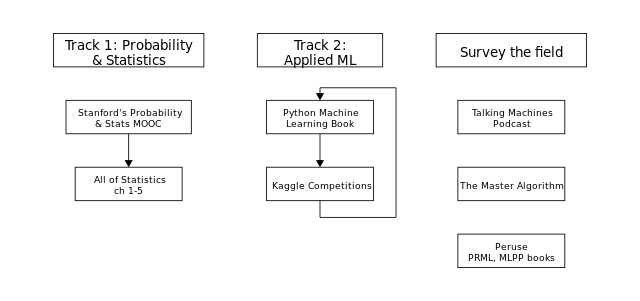
Track 1: Probability and Statistics
The goal of this track is to get comfortable with basic statistics and exploratory data analysis and to build a solid theoretical foundation in probability theory that will make thinking more rigorously about machine learning possible. IMHO it is insufficient to rely solely on the brief intros to probability contained at the beginning of many machine learning texts; eating your spinach early will pay off over and over again as you approach more advanced models and techniques later on. As Wasserman puts it in the preface to All of Statistics:
Using fancy tools like neural nets, boosting, and support vector machines without understanding basic statistics is like doing brain surgery before knowing how to use a band-aid.
Slowing way down and struggling through real math problems is key here. I’d often spend hours, sometimes days on a single problem. Getting stuck = real learning. I recommend finding a study buddy and/or expert who’s willing to help you get over the hump when you are truly stuck.
The track:
- Stanford’s Free online Probability and Statistics Course: a nice gentle introduction before approaching the more axiomatic coverage of Wasserman. Good coverage of basic exploratory data analysis too.
- The first 5 chapters of Wasserman’s All of Statistics text and problem sets from CMU’s intermediate stats course (from the author) and another more introductory counterpart
Supporting resources:
- Khan Academy’s videos on Probability and Statistics: I didn’t watch comprehensively, but did turn to for a second explanation many times.
- Math Monk’s YouTube playlist: Probability Primer: These felt like the missing MOOC lectures for Wasserman’s book
- UAH’s Random: Probability, Mathematical Statistics, Stochastic Processes: comprehensive coverage of many important topics in probability and statistics, including some illustrative web app/simulations and exercises.
- First Look at Rigorous Probability Theory: another good textbook that I bought and consulted for a second explanation on many of the topics covered in Wasserman
- Peter Norvig’s Introduction to Probability iPython Notebook
- Wikipedia’s outlines of Statistics and Probability
- IUPUI’s ECE 302 Probabilistic Methods in Electrical Engineering: course website with nicely written up homework and exam solutions.
- Penn State’s Stat 414/415 Course Materials: another good place to cross-reference concepts with some examples and solutions. I found perusing the section on functions of random variables helpful and wish I’d found it sooner!
- Guy Lebanon’s The Analysis of Data Vo1: Probability: Prof turned industry ML champ (LinkedIn, Netflix) published a free book on probability theory. A nice resource to cross-reference concepts covered in the 1st half of Wasserman. Guy also has a bunch of notes on his website that are interesting to peruse.
- Seeing Theory: very nice visualizations to aid understanding of fundamental concepts in probability and statistics
What I appreciate about the All of Statistics book compared to others I’ve looked at, including my text from college, is that it doesn’t spend too much time on counting methods (knowing how many ways one can deal a full house with a deck of cards isn’t particularly relevant) and is otherwise more comprehensive on probability theory most relevant to machine learning. It is concise and somewhat dry, but it serves as a great road map of topics to study; the supporting resources and lectures can provide additional context when necessary. Math Monk’s videos are a particularly nice companion.
Track 2: Applied Machine Learning
The goal of phase 2 is to build on the theoretical knowledge of probability theory from phase 1 to gain a richer, probabilistic understanding of machine learning, and build on the practical skills by diving into a more advanced topic.
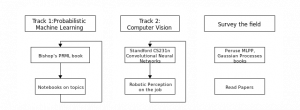
I think track 1 would be appropriate for everyone, and track 2 depends on what field of machine learning you are most interested in (and perhaps where you have taken a job!); in my case, it is computer vision, but could just as well be something like natural language processing, or bioinformatics.
Track 1: Probabilistic ML
The track:
Read and work through Bishop’s Pattern Recognition and Machine Learning book
Author notebooks about topics along the way (e.g Expectation Maximization
Supporting Resources:
Kevin Murphy’s Machine Learning from a Probabilistic Perspective: was a close second for the learning track. More comprehensive than PRML, but feels more like a great reference than a book to work through cover to cover.
Coursera course on Probabilistic Graphical Models: the original course has been broken into 3. I’ve found the video lectures a great complement to the coverage of graphical models in Bishop’s book.
Notebook Lectures from University of Michigan’s EECS 545 and EECS 445 Machine Learning courses (some of which I helped to develop!)
Mathematical Monk’s ML YouTube playlist
This track is all about going deeper into the theory underlying machine learning, often viewing models in terms of joint probability distributions. Why bother? Well, beyond viewing machine learning fields like supervised learning as a useful black box that can make predictions, being able to reason more soundly about how confident you are in the model’s predictions requires it. And as you wade into more advanced topics and bayesian methods, you will find you simply cannot understand the material without fluently seeing how things are modeled probabilistically, and reasoning about when and how you can infer the model from data, for instance, which models provide for exact inference, and which require sampling methods like MCMC.
Having spent time perusing both MLPP and PRML during phase 1 was helpful in determining which book to choose. I ultimately decided that MLPP was a better choice as I find it does a more thorough job covering the fundamentals and structuring the book to progress linearly. PRML both benefits and is burdened with nearly a decade more material, so it feels more like a really good and pretty thorough survey of nearly every field of ML. That it is nearly a thousand pages long also means it would be pretty impractical to attempt to read it cover to cover in a single 4-6 month phase. And while MLPP is “out of date”, everything in it is feels like essential material and should be covered before moving onto the more recent material covered in PRML.
Track 2: Computer Vision
The track:
- Stanford’s cs231n course materials and video lectures
Supporting resources:
- Hugo Larochelle’s deep learning lectures: could be a learning track in itself. It Covers conv-nets, great for cross-referencing.
- Understanding Higher Order Local Gradient Computation for Backpropagation in Deep Neural Networks: nice tips on reasoning about computing gradients of functions of tensors with respect to tensors from Daniel Seita, who TA’d the cs231n-like course at Berkeley
- Vector Deriviatives notes: more notes on computing derivatives of tensors from Erik Learned-Miller
Once I started a job helping with research related to autonomous vehicles, the most exciting practical application of ML became computer vision. Examples of core tasks include image classification (given an image, what is it), object detection (given an image, where are the things in it, and what are they) and pose detection (given this image of a person, how are they oriented). I’ve had a chance to learn a lot about a lot of topics, but a lot of focus on the state of the art involves various applications of deep convolutional neural networks. So I’m focusing on learning the fundamentals of convolutional neural networks instead of some of the more fundamental topics within computer vision like multi-view geometry.
Deep Learning (DL) and Keras
Definition
DL is a subfield of machine learning (ML) in artificial intelligence (AI) that deals with algorithms inspired by the biological structure and functioning of a brain to aid machines with intelligence.
Exploring the popular DL Frameworks:
Low-Level DL Frameworks
- Theano.
- Torch.
- Pytorch.
- TensorFlow.
High-Level DL Frameworks
Key Persons
2022
Chip Huyen
https://github.com/chiphuyen
2022
Chip Huyen
https://github.com/chiphuyen
I’m Chip Huyen, a writer and computer scientist. I grew up chasing grasshoppers in a small rice-farming village in Vietnam.